|
I received my Ph.D. degree in EECS at MIT CSAIL, advised by Prof. Pulkit Agrawal. My research interests revolve around robot learning (dexterous manipulation, locomotion, navigation). I received my master's degree from the Robotics Institute, Carnegie Mellon University (CMU RI) in May 2019, advised by Prof. Abhinav Gupta. Prior to this, I was a research engineer in Shanghai LX Robotics, where I conducted research on object detection, image segmentation, deep reinforcement learning in robotics, SLAM, etc. I earned my bachelor's degree from Shanghai Jiao Tong University (SJTU) in June 2016, majoring in mechanical engineering and automation. I was also an exchange student (GEARE program) at School of Mechanical Engineering, Purdue University. |

|
|
|
|
|
|
Tao Chen, Eric Cousineau, Naveen Kuppuswamy, Pulkit Agrawal International Conference on Robotics and Automation (ICRA), 2025 project page / arXiv A robotic system that peels vegetables with a dexterous robot hand. |
|
Tao Chen, Megha Tippur, Siyang Wu, Vikash Kumar, Edward Adelson, Pulkit Agrawal Science Robotics, 2023 Science Robotics paper / arXiv / project page / code / bibtex author = {Tao Chen and Megha Tippur and Siyang Wu and Vikash Kumar and Edward Adelson and Pulkit Agrawal }, title = {Visual dexterity: In-hand reorientation of novel and complex object shapes}, journal = {Science Robotics}, volume = {8}, number = {84}, pages = {eadc9244}, year = {2023}, doi = {10.1126/scirobotics.adc9244}, URL = {https://www.science.org/doi/abs/10.1126/scirobotics.adc9244}, eprint = {https://www.science.org/doi/pdf/10.1126/scirobotics.adc9244}, } A real-time controller that dynamically reorients complex and novel objects by any amount using a single depth camera. |
|
Marcel Torne, Anthony Simeonov, Zechu Li, April Chan, Tao Chen, Abhishek Gupta, Pulkit Agrawal Robotics: Science and Systems (RSS) , 2024 arXiv / project page Improve the robustness of imitation learning policies with a real-to-sim-to-real approach. |

|
Meenal Parakh*, Alisha Fong*, Anthony Simeonov, Tao Chen, Abhishek Gupta, Pulkit Agrawal (*equal contribution) International Conference on Robotics and Automation (ICRA), 2023 paper / project page / bibtex title={Lifelong Robot Learning with Human Assisted Language Planners}, author={Parakh, Meenal and Fong, Alisha and Simeonov, Anthony and Chen, Tao and Gupta, Abhishek and Agrawal, Pulkit}, journal={arXiv preprint arXiv:2309.14321}, year={2023} } } An LLM-based task planner that can learn new skills opens doors for continual learning. |
|
Marcel Torne, Max Balsells, Zihan Wang, Samedh Desai, Tao Chen, Abhishek Gupta Advances in Neural Information Processing Systems (NeurIPS), 2023 paper / project page / code / bibtex title={Breadcrumbs to the Goal: Goal-Conditioned Exploration from Human-in-the-Loop Feedback}, author={Torne, Marcel and Balsells, Max and Wang, Zihan and Desai, Samedh and Chen, Tao and Agrawal, Pulkit and Gupta, Abhishek}, journal={Advances in Neural Information Processing Systems}, year={2023} } } Press coverage: MIT News Method for guiding goal-directed exploration with asynchronous human feedback. |
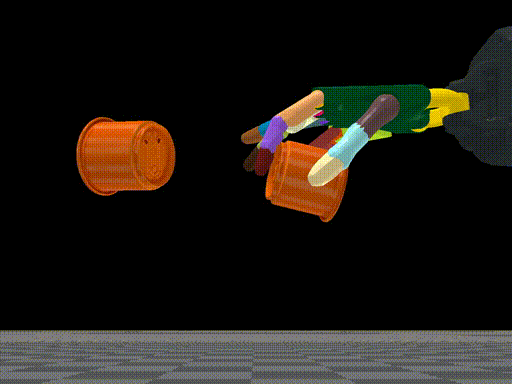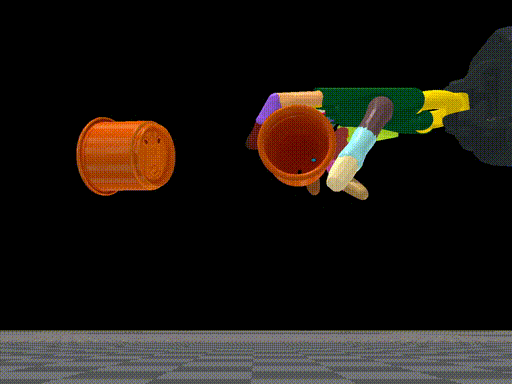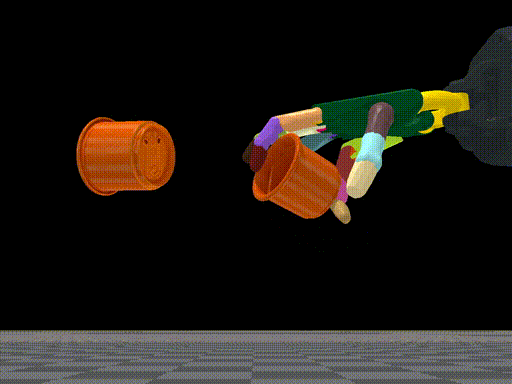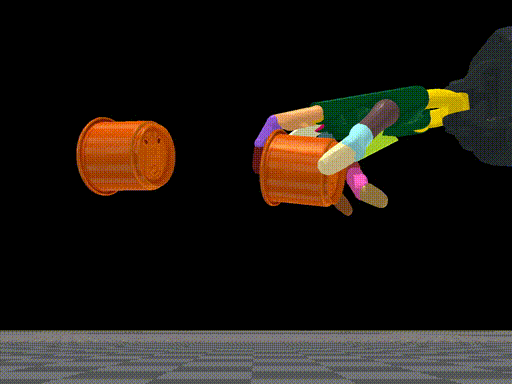
|
Tao Chen, Jie Xu, Pulkit Agrawal Conference on Robot Learning (CoRL), 2021 (Best Paper Award) paper / arXiv / bibtex / code / project page / oral talk title={A System for General In-Hand Object Re-Orientation}, author={Chen, Tao and Xu, Jie and Agrawal, Pulkit}, journal={Conference on Robot Learning}, year={2021} } Press coverage: MIT News, MIT CSAIL News, AZO Robotics, AIHub, AI科技评论, Tech Xplore, Communications of the ACM, Inceptive Mind, IEEE Spectrum, The Hack Posts, Tectales, The Robot Report A system for general in-hand object reorientation. |
|
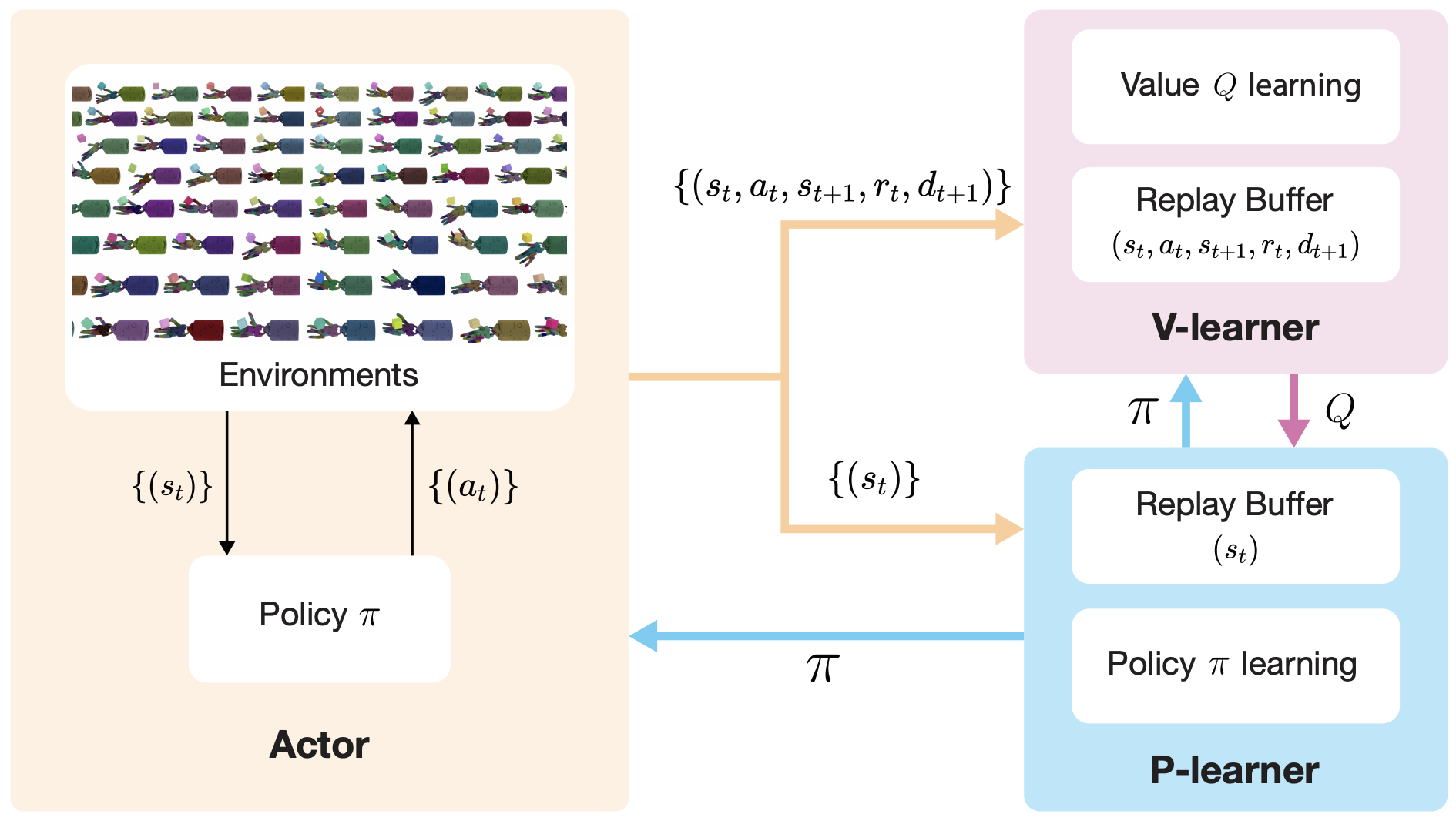
Zechu Li*, Tao Chen*, Zhang-Wei Hong, Anurag Ajay, Pulkit Agrawal (* indicates equal contribution) International Conference on Machine Learning (ICML) , 2023 bibtex / arXiv / Code title={Parallel $Q$-Learning: Scaling Off-policy Reinforcement Learning under Massively Parallel Simulation}, author={Li, Zechu and Chen, Tao and Hong, Zhang-Wei and Ajay, Anurag and Agrawal, Pulkit}, journal={International Conference on Machine Learning}, year={2023} } Scale up off-policy algorithms with more than 10K parallel environments on a single workstation |
|
Sameer Pai*, Tao Chen*, Megha Tippur*, Edward Adelson, Abhishek Gupta†, Pulkit Agrawal† (* indicates equal contribution, † indicates equal advising) International Conference on Robotics and Automation (ICRA) , 2023 bibtex / project page / arXiv title={TactoFind: A Tactile Only System for Object Retrieval}, author={Pai, Sameer and Chen, Tao and Tippur, Megha and Adelson, Edward and Gupta, Abhishek and Agrawal, Pulkit}, journal={International Conference on Robotics and Automation}, year={2023} } Localize, identify, and fetch a target object in the dark with tactile sensors |

|
Sizhe Li, Zhiao Huang, Tao Chen, Tao Du, Hao Su, Joshua B. Tenenbaum, Chuang Gan International Conference on Learning Representations (ICLR) , 2023 bibtex / arXiv / Code / Project page title={DexDeform: Dexterous Deformable Object Manipulation with Human Demonstrations and Differentiable Physics}, author={Li, Sizhe and Huang, Zhiao and Chen, Tao and Du, Tao and Su, Hao and Tenenbaum, Joshua B and Gan, Chuang}, journal={International Conference on Learning Representations}, year={2023} } Dexterous manipulation with deformable objects |
|
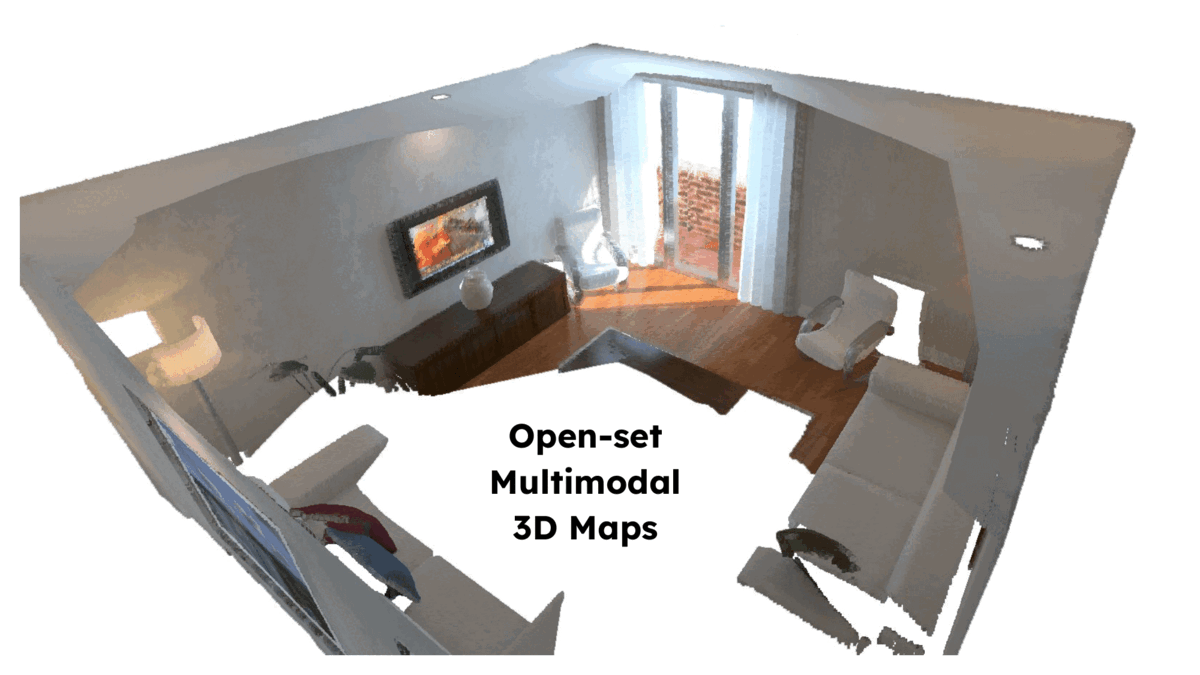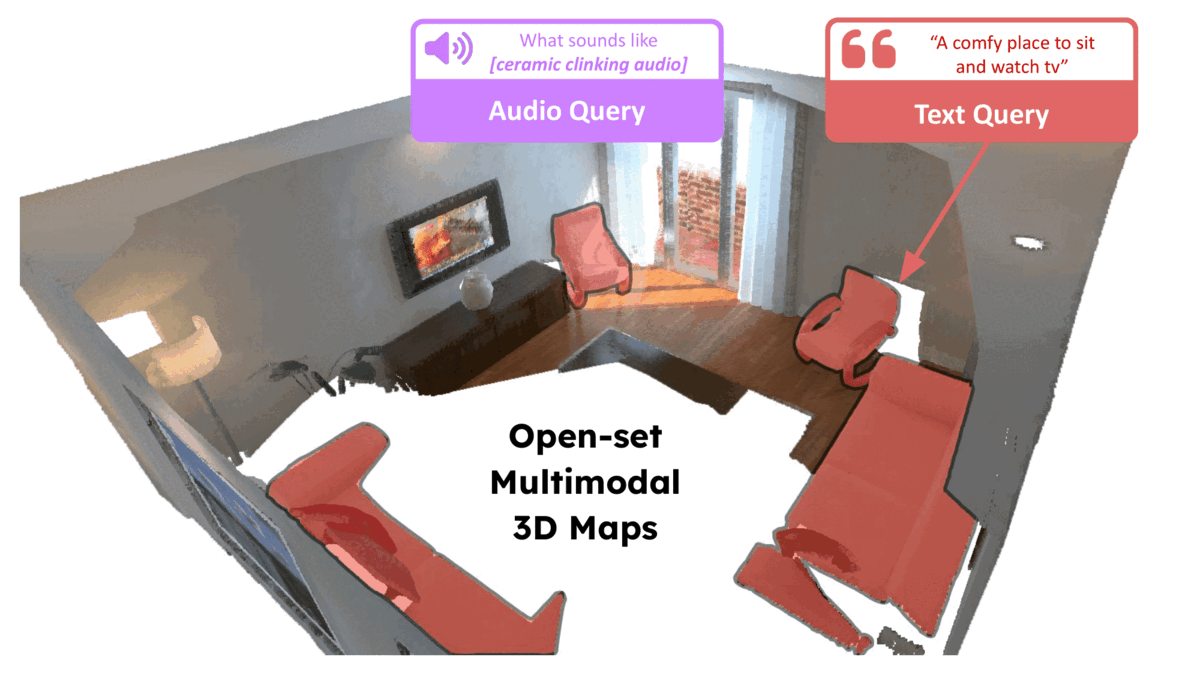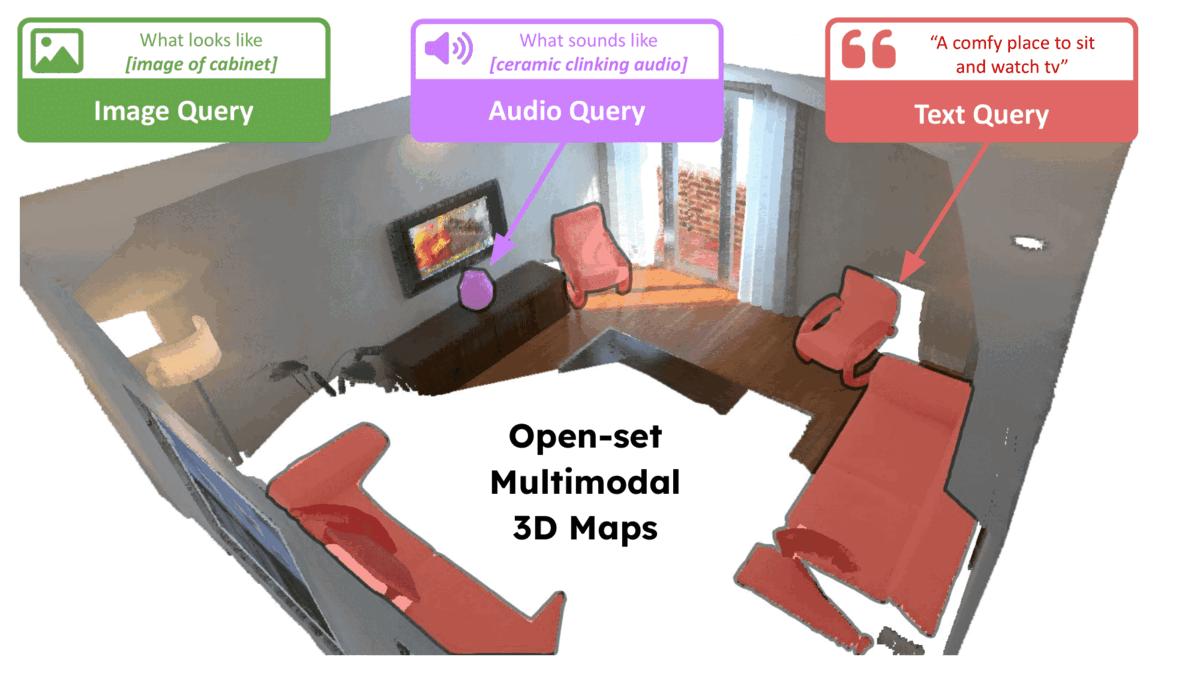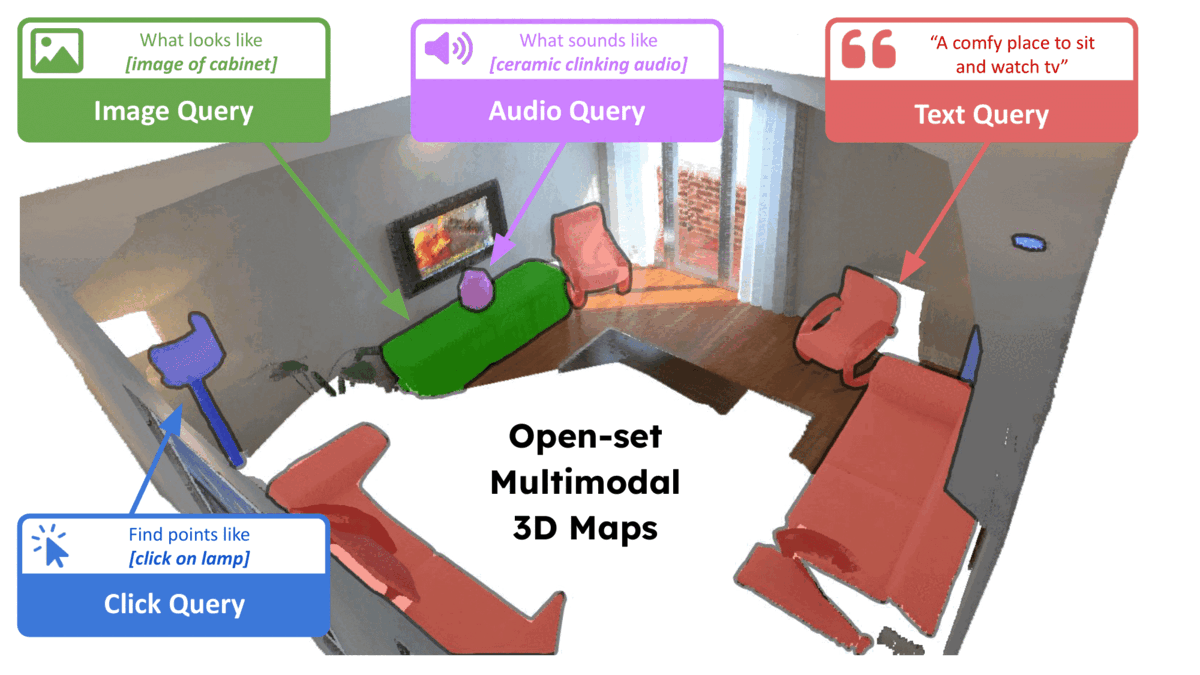
Krishna Murthy Jatavallabhula, Alihusein Kuwajerwala, Qiao Gu, Mohd Omama, Tao Chen, Shuang Li, Ganesh Iyer, Soroush Saryazdi, Nikhil Keetha, Ayush Tewari, Joshua B. Tenenbaum, Celso Miguel de Melo, Madhava Krishna, Liam Paull, Florian Shkurti, Antonio Torralba Robotics: Science and Systems (RSS) , 2023 bibtex / arXiv / Code / Project page title={Conceptfusion: Open-set multimodal 3d mapping}, author={Jatavallabhula, {Krishna Murthy} and Kuwajerwala, Alihusein and Gu, Qiao and Omama, Mohd and Chen, Tao and Li, Shuang and Iyer, Ganesh and Saryazdi, Soroush and Keetha, Nikhil and Tewari, Ayush and Tenenbaum, {Joshua B.} and {de Melo}, {Celso Miguel} and Krishna, Madhava and Paull, Liam and Shkurti, Florian and Torralba, Antonio}, journal={Robotics: Science and Systems}, year={2023} } A scene representation that allows for multi-modal (language, image, audio, etc.) and open-set queries |

|
Jie Xu, Sangwoon Kim, Tao Chen, Alberto Rodriguez, Pulkit Agrawal, Wojciech Matusik, Shinjiro Sueda Conference on Robot Learning (CoRL), 2022 paper / bibtex / project page / title={Efficient Tactile Simulation with Differentiability for Robotic Manipulation}, author={Jie Xu and Sangwoon Kim and Tao Chen and Alberto Rodriguez Garcia and Pulkit Agrawal and Wojciech Matusik and Shinjiro Sueda}, booktitle={6th Annual Conference on Robot Learning}, year={2022}, url={https://openreview.net/forum?id=6BIffCl6gsM} } Tactile Simulator for complex shapes training on which transfers to real-world. |

|
Gabriel Margolis, Ge Yang, Kartik Paigwar, Tao Chen, Pulkit Agrawal Robotics: Science and Systems (RSS), 2022 paper / project page / bibtex / video / title={Rapid Locomotion via Reinforcement Learning}, author={Margolis, Gabriel B and Yang, Ge and Paigwar, Kartik and Chen, Tao and Agrawal, Pulkit}, journal={Robotics: Science and Systems}, year={2022} } Press coverage: Wired, Popular Science, TechCrunch, BBC , MIT News High-speed running and spinning on diverse terrains with a RL based controller. |
|
Yu-Wei Chao, Chris Paxton, Yu Xiang, Wei Yang, Balakumar Sundaralingam, Tao Chen, Adithya Murali, Maya Cakmak, Dieter Fox International Conference on Robotics and Automation (ICRA) , 2022 arXiv / bibtex / project page / code title={HandoverSim: A Simulation Framework and Benchmark for Human-to-Robot Object Handovers}, author={Chao, Yu-Wei and Paxton, Chris and Xiang, Yu and Yang, Wei and Sundaralingam, Balakumar and Chen, Tao and Murali, Adithyavairavan and Cakmak, Maya and Fox, Dieter}, journal={International Conference on Robotics and Automation}, year={2022} } 1000 handover scenes captured from the real world, reproduced in simulation |
|
Zhang-Wei Hong, Tao Chen, Yen-Chen Lin, Joni Pajarinen, Pulkit Agrawal International Conference on Learning Representations (ICLR), 2022 paper / bibtex / video / hong2022topological, title={Topological Experience Replay}, author={Hong, Zhang-Wei and Chen, Tao and Lin, Yen-Chen and Pajarinen, Joni and Agrawal, Pulkit}, booktitle={In Proceedings of The Tenth International Conference on Learning Representations }, year={2022}, url={https://openreview.net/forum?id=OXRZeMmOI7a}, } A fast Q-learning method by building a topological graph in the replay buffer. |

|
Gabriel Margolis, Tao Chen, Kartik Paigwar, Xiang Fu, Donghyun Kim, Sangbae Kim, Pulkit Agrawal Conference on Robot Learning (CoRL), 2021 paper / bibtex / project page title={Learning to Jump from Pixels}, author={Margolis, Gabriel and Chen, Tao and Paigwar, Kartik and Fu, Xiang and Kim, Donghyun and Kim, Sangbae and Agrawal, Pulkit}, journal={Conference on Robot Learning}, year={2021} } Press Coverage: MIT News, AZO Robotics, The Robot Report A hierarchical control framework for dynamic vision-aware locomotion. |
|
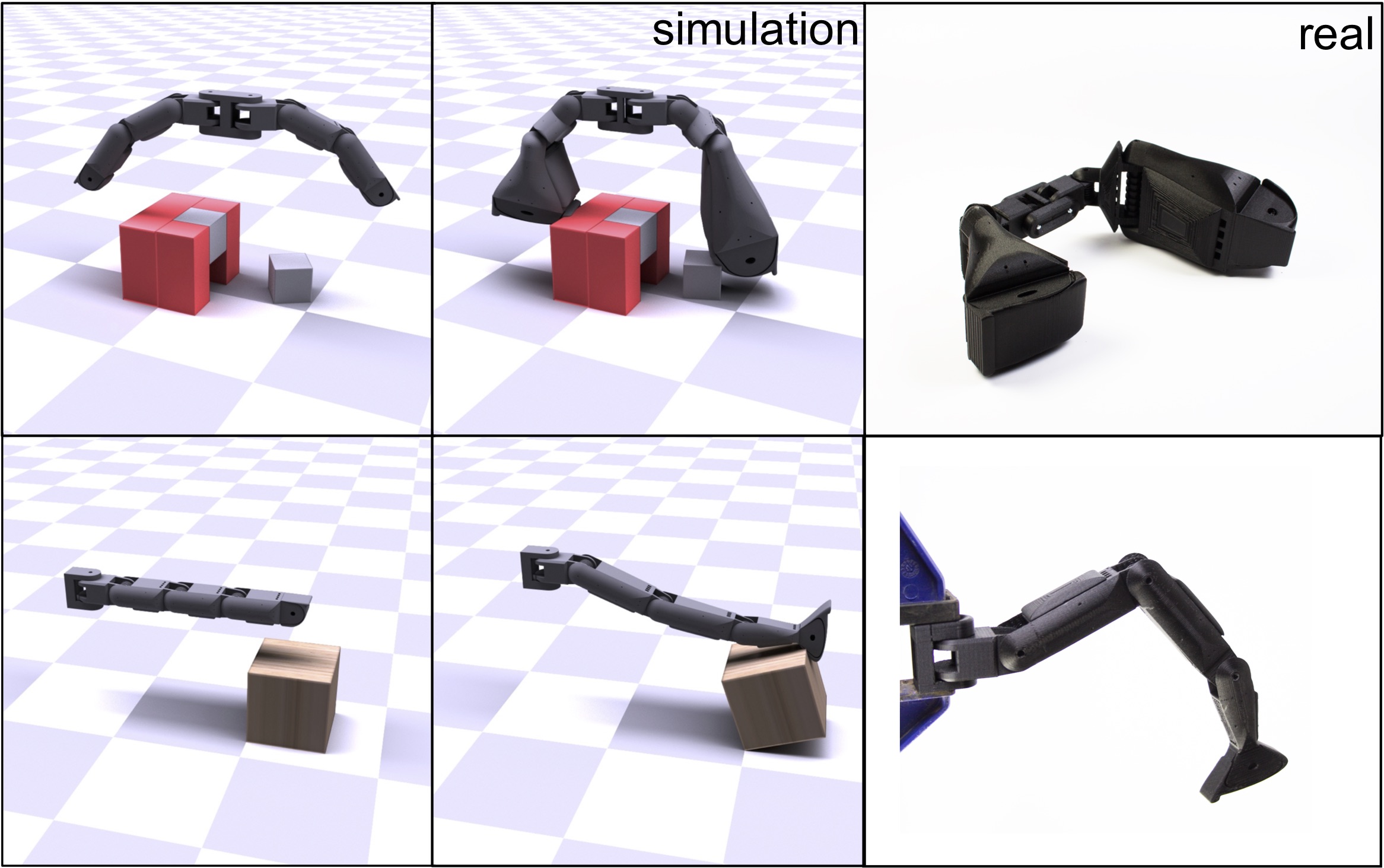
Jie Xu, Tao Chen, Lara Zlokapa, Michael Foshey, Wojciech Matusik, Shinjiro Sueda, Pulkit Agrawal Robotics: Science and Systems (RSS) , 2021 paper / arXiv / bibtex / project page / code / video / talk title={An End-to-End Differentiable Framework for Contact-Aware Robot Design}, author={Xu, Jie and Chen, Tao and Zlokapa, Lara and Matusik, Wojciech and Sueda, Shinjiro and Agrawal, Pulkit}, journal={Robotics: Science and Systems}, year={2021} } Press Coverage: MIT News, Tectales Computational method for design task-specific robotic hands. |
|
|
Joshua Gruenstein, Tao Chen, Neel Doshi, Pulkit Agrawal IEEE International Conference on Robotics and Automation (ICRA) , 2021 paper / bibtex / project page / video title={Residual Model Learning for Microrobot Control}, author={Gruenstein, Joshua and Chen, Tao and Doshi, Neel and Agrawal, Pulkit}, journal={International Conference on Robotics and Automation}, year={2021} } A data-efficient learning method for controlling microrobots with complex dynamics. |
|
Xiang Fu, Tao Chen, Pulkit Agrawal, Tommi S. Jaakkola NeurIPS Biological and Artifical RL workshop, 2020 paper / bibtex author = {Xiang Fu and Tao Chen and Pulkit Agrawal and Tommi Jaakkola}, title = {Language Inference for Reward Learning}, booktitle = {Advances in Neural Information Processing Systems Workshop (Biological and Artificial Reinforcement Learning)}, year = {2020} } Reward learning by using formal language (regular expression) to capture the reward structure. |
|
Tao Chen, Pulkit Agrawal ICML BIG workshop, 2020 paper(workshop version) / bibtex / project page author = {Tao Chen and Pulkit Agrawal}, title = {Learning to Learn from Failures using Replay}, booktitle = {International Conference on Machine Learning Workshop (Inductive Biases, Invariances and Generalization in RL)}, year = {2020} } Remembering failures aids faster learning by preventing the agent to oscillate between mistakes. |
|
|
An easy-to-use python interface for robot learning and a low-cost robot learning platform. |
|
A framework for learning to explore novel environments with on-board sensors in the testing time. |
|
|
|
One policy to control many robots that are kinematically and dynamically different. |
|
|
A four-fingered soft gripper with multi-cavity pneumatic elastomer actuators (MCPEA) for grasping objects with different sizes, shapes, fragility. |
|
|
|
|
A key step for robots to get popularized into our daily life is that robots should be able to automatically explore the new environment when they are deployed in new houses or buildings. In this project, I combine the strength of motion planning (OMPL and SBPL), frontier-based exploration, SLAM (ORB-SLAM2), and object recognition and segmentation (FCIS) techniques to build an automatic mapping system that can autonomously explore the new houses, recognize daily objects and remember their locations while keep building the dense map as it moves. After the map is built, the robot can be asked to find and move to the objects it has seen (like cup, monitor) autonomously. |
|
|
|
|
|
|
|
|
|
|
|
|
|
We combined the symbolic planning and supervised learning to efficiently learn to move a set of blocks from an initial configuration to a goal configuration (a.k.a, robot construction problem). The symbolic planning module plans the sequence actions (path) to move the blocks (a block or a sub-assembly) to reach the goal configurations. The supervised learning module (stability checker) predicts whether the state (RGB image) is stable or not so that the planning module only plans with the actions that lead to stable states. We used domain randomization techniques to generate more diversified visual data to make the stability checker more robust. These two modules combined lead to an effective way to solve the robot construction problem. |
|
|
This project was the Senior Engineering Design Capstone project at Purdue University. We built an aesthetically pleasing tennis ball collecting robot which can collect tennis balls dispersed on a tennis court. I was fully responsible for all the programming and control tasks for the robot. |
|
|
This competition was a real-life version of Counter-Strike game with real mobile robots. I led and managed the mechanical group. We won the second prize in 2015 National RoboMaster Robotics Competition of east China and the third prize in 2015 National RoboMaster Robotics Competition Final. |
|
|
|
We designed and built an inexpensive yet effective elbow joint rehabilitation device. The device is only composed of mechanical parts such as a lead screw, and a four-bar mechanism. It can help patients exercise their elbow joints in an inexpensive way, and it is also very easy to use and portable. We have applied a patent (Application Number: CN201510472161.5, Publication Number: CN105148460B) for this rehabilitation device. |


|
We built a high-adaptability track robot with two separate frames. I led and managed the team and I was responsible for electronic control, programming, and part of manufacturing. |
|
|
| Reviewer for ICLR (Outstanding Reviewer), CoRL, NeurIPS, ICML, RSS, ICRA, IROS, RoboSoft, Humanoids, TPAMI, TII, T-RO etc. |
|
|